贝叶斯优化
许多机器学习模型都有一组需要在训练之前设定的超参数,例如学习率、正则化强度、树深度和 batch size。一次完整训练可能需要几分钟、几小时,甚至几天,因此我们不能穷举所有组合。
贝叶斯优化(Bayesian Optimization, BO)就是为这类“每试一次都很贵”的黑盒优化问题准备的。它不会盲目地试点,而是用已有观测建立一个带不确定性的代理模型,再决定下一次最值得评估的位置。
本文中的 GP 贝叶斯优化会用到 高斯过程 的后验均值和方差。
贝叶斯优化的目标
设目标函数为
我们想在可行域 \(\mathcal X\) 内找到
如果实际问题是最小化损失 \(L(x)\),只需要令 \(f(x)=-L(x)\),或在算法中直接使用最小化版本。
贝叶斯优化常用于满足以下特点的问题:
- 目标函数是黑盒:只能输入 \(x\) 并观测 \(f(x)\),没有显式表达式。
- 评估代价高:一次实验、仿真或模型训练很慢。
- 无法使用梯度:函数可能不可导、含离散变量,或系统根本不返回梯度。
- 目标可能含噪声:同一组参数多次评估可能得到不同结果。
- 评估预算有限:我们关心的不是代理模型处处准确,而是在少量评估中尽快找到好解。
所以,它和梯度下降解决的问题不同:梯度下降通常在单次训练内更新模型参数,而贝叶斯优化通常位于外层,用来选择下一次完整实验的超参数。
主动学习与贝叶斯优化
主动学习和贝叶斯优化都会根据当前模型选择下一个查询点,但它们的目标不同。
- 主动学习希望用尽量少的标注让模型在整个输入空间更准确,因此常优先查询不确定性最高的位置。
- 贝叶斯优化只关心快速找到最优值。对于已知表现很差的区域,即使代理模型还不准确,也可能没必要继续浪费评估预算。
贝叶斯优化始终在两种行为之间权衡:
- 利用(exploitation):在当前认为目标值高的区域继续精细搜索。
- 探索(exploration):去尝试不确定性较大、但有可能藏着更好结果的区域。
贝叶斯优化的核心流程
在第 \(t\) 轮,我们已经有一组观测数据
一次标准迭代由两个主要部件完成:
- 代理模型(surrogate model):用便宜的概率模型近似昂贵的真实目标函数。
- 采集函数(acquisition function):根据代理模型的预测和不确定性,评估每个候选点有多值得尝试。
完整流程为:
- 定义搜索空间 \(\mathcal X\) 和目标函数。
- 选择少量初始点,获得初始数据 \(\mathcal D_0\)。
- 用当前数据拟合代理模型,得到后验分布。
- 构造采集函数 \(\alpha_t(x)\)。
- 优化采集函数,选择下一个评估点
- 评估真实黑盒函数 \(y_{t+1}=f(x_{t+1})\),并更新数据集。
- 重复上述过程,直到预算用完或改进已经很小。
1 | initialize D with a few evaluations |
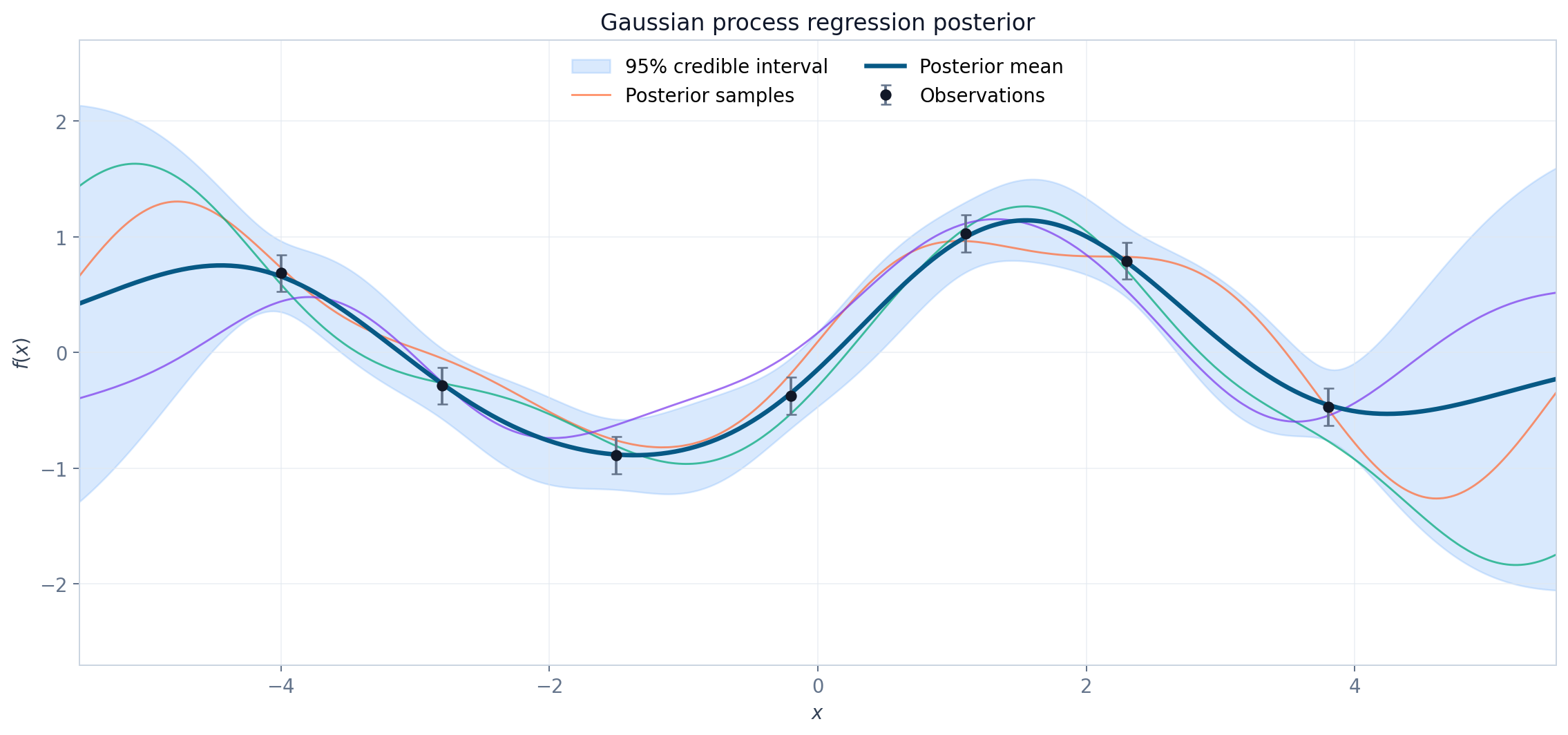
高斯过程代理模型
经典贝叶斯优化常使用高斯过程(GP)作为代理模型。在给定已观测数据 \(\mathcal D_t\) 后,对每个候选点 \(x\),GP 会给出高斯后验
其中:
- \(\mu_t(x)\) 表示当前对目标函数的最佳估计。
- \(\sigma_t(x)\) 表示对该估计的不确定程度。
在已观测点附近,不确定性通常较小;远离数据的区域,不确定性通常较大。采集函数就是将 \(\mu_t(x)\) 与 \(\sigma_t(x)\) 组合成一个便于优化的分数。

图 1:上图是黑盒目标、GP 后验均值和可信带;下图是 EI。红色虚线位置就是下一个要评估的点。
采集函数
下面统一考虑最大化问题。记当前已观测到的最佳目标值为
\(\xi\ge 0\) 或 \(\kappa>0\) 是控制探索程度的参数。
改进概率 PI
改进概率(Probability of Improvement, PI)关心“新点超过当前最佳值的概率有多大”:
当 GP 后验标准差 \(\sigma_t(x)>0\) 时,它可写成
其中 \(\Phi\) 是标准正态分布的累积分布函数。
PI 只关心“能否改进”,不关心“改进多少”。一个几乎肯定只会提高一点点的位置,可能比一个风险较高但潜在收益很大的位置获得更高的 PI。
期望改进 EI
期望改进(Expected Improvement, EI)将改进量定义为
并使用其后验期望作为采集分数:
对高斯后验,EI 有解析形式
其中 \(\phi\) 是标准正态密度函数。当 \(\sigma_t(x)=0\) 时,EI 取 \(0\)。
第一项偏向当前均值较高的区域,对应利用;第二项奖励不确定性,对应探索。这使 EI 成为最常用的采集函数之一。
置信上界 UCB
置信上界(Upper Confidence Bound, UCB)直接将均值与标准差线性组合:
\(\kappa\) 较小时偏向利用,较大时偏向探索。如果是最小化问题,可使用置信下界 \(\mu_t(x)-\kappa\sigma_t(x)\) 并取其最小值。

图 2:不同采集函数对“利用当前高值”和“探索高不确定性”的权衡不同,因此可能选择不同的下一个点。
Thompson Sampling
Thompson Sampling 每轮从代理模型的后验中抽取一条可能的函数
然后选择这条函数的最优点:
高不确定性区域中,抽样函数变化较大,有机会在这些区域出现很高的峰,因而自然实现探索;后验均值较高的区域又更容易成为抽样函数的最优点,因而也会利用已有信息。
随机搜索
随机搜索不使用后验信息,但它仍然是重要基线。在搜索维度不高、单次评估并不昂贵,或目标函数极不平滑时,随机搜索可能已经足够。在检验贝叶斯优化是否真正带来收益时,应该始终与相同评估预算下的随机搜索比较。
TPE:从“预测目标”转向“建模好参数”
Tree-structured Parzen Estimator(TPE)也属于序列模型优化,但它与 GP 的建模方向不同。
- GP 直接建模 \(p(y\mid x)\),询问“给定参数 \(x\),结果 \(y\) 的分布是什么?”
- TPE 建模 \(p(x\mid y)\) 和 \(p(y)\),询问“给定结果的好坏,哪些参数 \(x\) 更常出现?”
下面改用最小化损失的记号。选择损失阈值 \(y^*\),使
实际中,\(y^*\) 通常取已观测损失的某个较小分位数。然后将参数观测分成两组:
- \(l(x)\) 由损失较小的 good group 估计。
- \(g(x)\) 由剩余的 bad group 估计。
根据全概率公式,有
TPE 使用 Parzen 窗或类似的核密度估计来构造 \(l(x)\) 和 \(g(x)\)。经过贝叶公式变形后,期望改进与下式成比例:
因此,最大化 EI 等价于倾向选择 \(l(x)/g(x)\) 较大的点:该参数在“好结果”中很常见,但在“差结果”中不常见。

图 3:左侧用分位数阈值将观测分为 good 和 bad 两组;右侧分别估计 \(l(x)\) 与 \(g(x)\),并在 good 密度相对更高的区域生成下一批候选点。
什么是 Tree-structured
超参数空间常带有条件结构。例如:
- 只有优化器选择
SGD时,momentum才有意义。 - 只有模型选择决策树时,
max_depth才有意义。 - 网络层数决定了后续需要定义多少个“每层节点数”参数。
这种“选择一个参数后,才激活下一组参数”的搜索空间可以用树结构表示。TPE 特别适合连续、整数、类别和条件参数混合的超参数搜索。
GP 与 TPE 的对比
| 特点 | GP 贝叶斯优化 | TPE |
|---|---|---|
| 建模对象 | \(p(y\mid x)\) | \(p(x\mid y)\) |
| 不确定性 | 通过 GP 后验方差直接表示 | 通过 good/bad 密度的相对大小间接表示 |
| 常见采集准则 | PI、EI、UCB、Thompson Sampling | 最大化与 \(l(x)/g(x)\) 相关的 EI |
| 搜索空间 | 更适合低到中维、连续且相对平滑的问题 | 容易处理离散、类别和树状条件空间 |
| 计算瓶颈 | GP 核矩阵随观测数增长 | 密度估计和候选采样 |
这并不意味着某一种方法始终更好。代理模型是对目标函数结构的假设,它能否表达真实目标,会直接决定贝叶斯优化的效果。
用 Optuna 进行 TPE 超参数搜索
下面是一个精简的 Optuna 例子。目标函数应该在固定的验证集或交叉验证上返回损失,不要使用测试集调参。
1 | import optuna |
n_startup_trials 表示在 TPE 开始建模之前先做多少次初始采样。样本太少时,\(l(x)\) 和 \(g(x)\) 的密度估计不稳定,因此算法需要一个初始探索阶段。
实践中容易忽略的问题
搜索空间的尺度
学习率、正则化强度等跨越多个数量级的参数,应在对数空间中搜索。将学习率均匀地限制在 \([10^{-6},1]\) 的原始空间,会把绝大多数试验浪费在较大数值上。
噪声与重复评估
随机初始化、mini-batch 顺序和数据划分都会让目标带有噪声。可以考虑:
- 固定随机种子,减少不必要的方差。
- 对最有希望的配置做多次重复评估。
- 让代理模型显式包含观测噪声。
- 使用交叉验证均值,并记录标准差。
失败试验和约束
某些超参数组合可能导致显存溢出、数值发散或训练超时。不要简单丢弃这些信息;应当记录失败原因,返回明确的惩罚值,或使用带可行性模型的约束贝叶斯优化。
并行评估
经典贝叶斯优化是序列的:看到上一次结果后才能决定下一点。多机并行时,同一批候选点之间可能缺少信息交流。可以使用 batch acquisition、对正在运行的试验做幻想观测,或接受少量样本效率损失来换取更高的计算吞吐量。
早停与评估预算
贝叶斯优化决定“下一次试什么”,早停则决定“当前这次还要不要继续”。两者结合往往比只使用其中一个更节省计算资源。
什么时候不必使用贝叶斯优化
贝叶斯优化并不是通用的优化捷径。以下情况可能更适合其他方法:
- 单次评估非常便宜:大规模随机搜索或网格搜索更简单。
- 可以获得准确梯度:梯度方法往往更高效。
- 维度很高且只有极少数据:代理模型难以从少量观测中学到有用结构。
- 目标随机性远大于超参数影响:代理模型很难判断哪些区域真正更好。
- 目标函数随时间快速变化:过去的观测可能已不能代表当前问题。
小结
贝叶斯优化可以概括为一个不断循环的问题:
根据已经看到的结果和仍然存在的不确定性,下一次昂贵评估应该花在哪里?
GP 贝叶斯优化通过后验均值和方差描述这个问题,PI、EI、UCB 和 Thompson Sampling 用不同方式平衡探索与利用。TPE 则转而建模好参数与差参数的密度,因而容易处理复杂、条件化的超参数空间。
贝叶斯优化的优势不在于每次决策一定正确,而在于它能将每次昂贵试验的结果转化为下一次决策的信息。