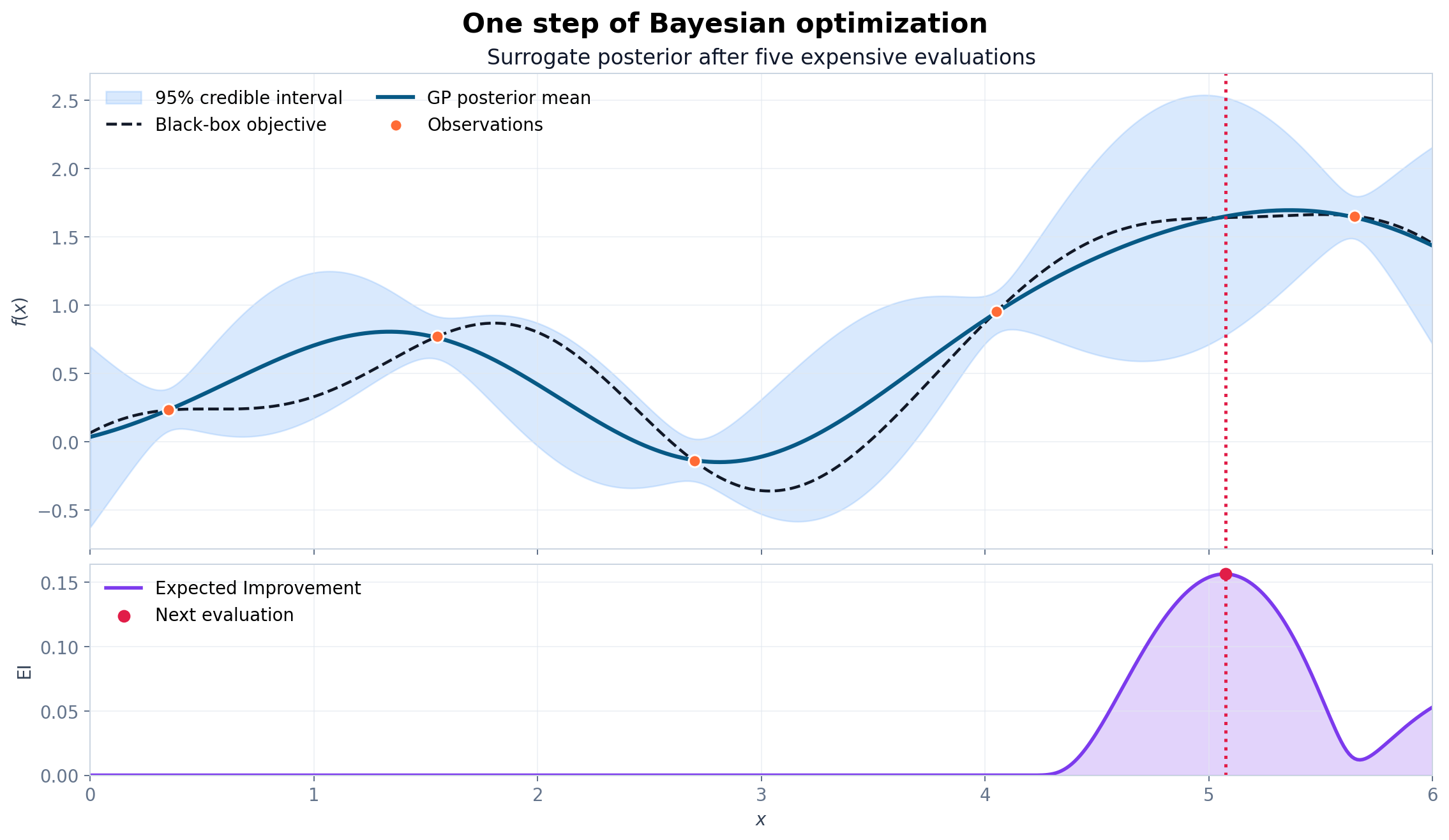
贝叶斯优化
许多机器学习模型都有一组需要在训练之前设定的超参数,例如学习率、正则化强度、树深度和 batch size。一次完整训练可能需要几分钟、几小时,甚至几天,因此我们不能穷举所有组合。 贝叶斯优化(Bayesian Optimization, BO)就是为这类“每试一次都很贵”的黑盒优化问题准备的。它不会盲目地试点,而是用已有观测建立一个带不确定性的代理模型,再决定下一次最值得评估的位置。 本文中的 GP 贝叶斯优化会用到 高斯过程 的后验均值和方差。 贝叶斯优化的目标设目标函数为 \[f:\mathcal X\rightarrow\mathbb R,\] 我们想在可行域 \(\mathcal X\) 内找到 \[x^*=\operatorname*{argmax}_{x\in\mathcal X}f(x).\] 如果实际问题是最小化损失 \(L(x)\),只需要令 \(f(x)=-L(x)\),或在算法中直接使用最小化版本。 贝叶斯优化常用于满足以下特点的问题: 目标函数是黑盒:只能输入 \(x\) 并观测 \(f(x)\),没有显式表达式。 评估代价高:一次...
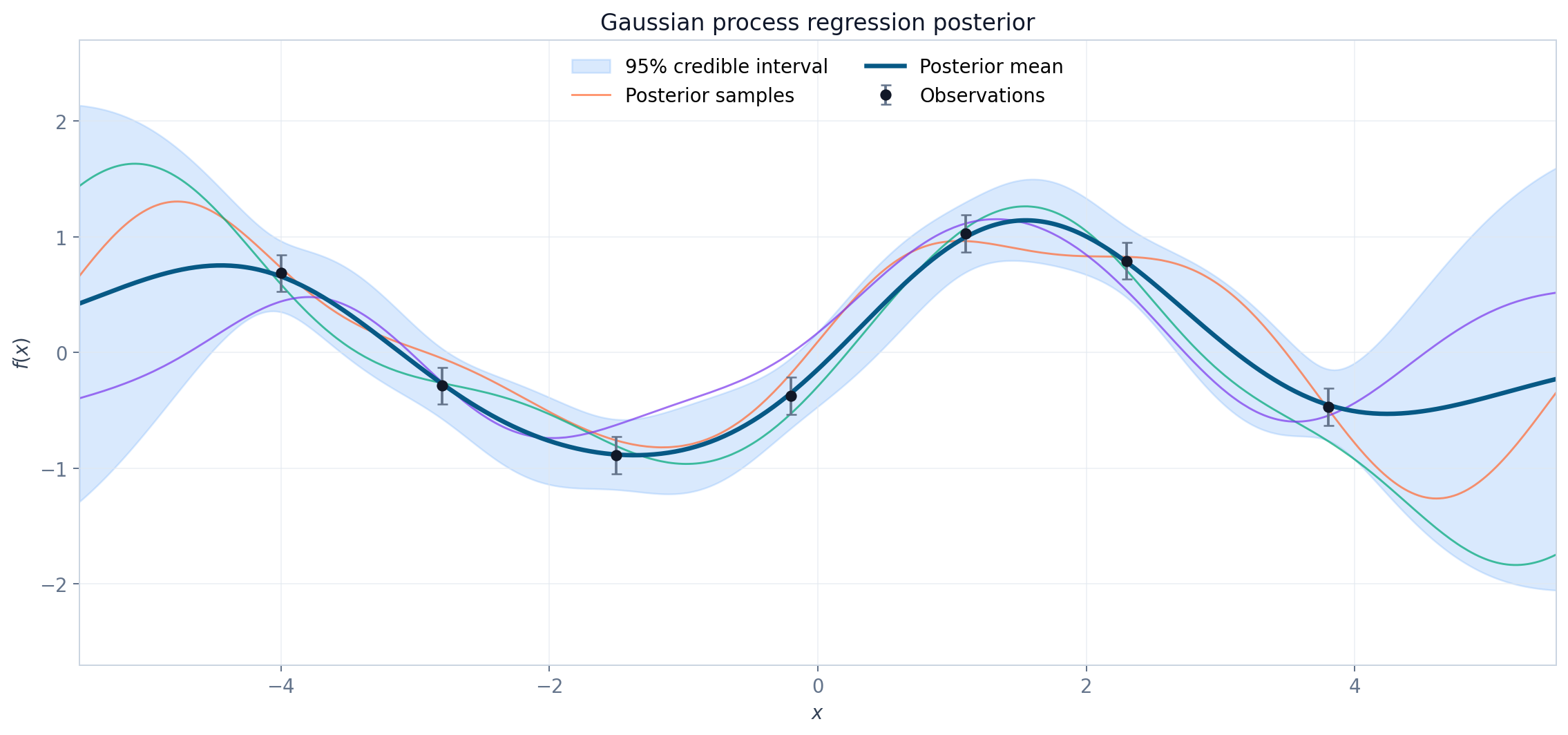
高斯过程
在概率与统计中,我们学习过高斯分布,也称正态分布。这一次,我想学习它在“函数空间”中的进阶版本:高斯过程(Gaussian Process, GP)。 高斯过程不是只给出一条拟合曲线,而是给出一组可能的函数及其概率。因此,它既能预测,也能告诉我们“这个预测有多不确定”。 随机过程一个随机变量只描述一次随机试验的结果,而随机过程描述一组随着时间、空间或其他索引变化的随机变量。 设 \(T\) 是索引集,随机过程写作 \[\{X(t):t\in T\}.\] 当 \(t\) 表示时间时,每一个固定的 \(t\) 都对应一个随机变量 \(X(t)\);而固定一次随机试验的结果后,\(t\mapsto X(t)\) 又会形成一条确定的样本路径。 理论上,一个随机过程可以由所有有限维分布描述:任取 \(t_1,\ldots,t_n\in T\),考察随机向量 \[\bigl(X(t_1),\ldots,X(t_n)\bigr)^\mathsf{T}.\] 高斯过程的特别之处就在于:上述任意有限维随机向量都服从多元高斯分布。 从一元到多元高斯分布一元高斯分布若 \(X\sim\mathcal...