在概率与统计中,我们学习过高斯分布,也称正态分布。这一次,我想学习它在“函数空间”中的进阶版本:高斯过程 (Gaussian Process, GP)。
高斯过程不是只给出一条拟合曲线,而是给出一组可能的函数及其概率。因此,它既能预测,也能告诉我们“这个预测有多不确定”。
随机过程 一个随机变量只描述一次随机试验的结果,而随机过程描述一组随着时间、空间或其他索引变化的随机变量。
设 \(T\) 是索引集,随机过程写作
\[\{X(t):t\in T\}.\]
当 \(t\) 表示时间时,每一个固定的 \(t\) 都对应一个随机变量 \(X(t)\);而固定一次随机试验的结果后,\(t\mapsto X(t)\) 又会形成一条确定的样本路径。
理论上,一个随机过程可以由所有有限维分布描述:任取 \(t_1,\ldots,t_n\in T\),考察随机向量
\[\bigl(X(t_1),\ldots,X(t_n)\bigr)^\mathsf{T}.\]
高斯过程的特别之处就在于:上述任意有限维随机向量都服从多元高斯分布。
从一元到多元高斯分布 一元高斯分布 若 \(X\sim\mathcal N(\mu,\sigma^2)\),其概率密度为
\[p(x)=\frac{1}{\sqrt{2\pi}\sigma}
\exp\left[-\frac{(x-\mu)^2}{2\sigma^2}\right].\]
均值 \(\mu\) 决定分布中心,方差 \(\sigma^2\) 决定分布的宽窄。
多元高斯分布的参数 对 \(d\) 维随机向量 \(\boldsymbol{x}\),若
\[\boldsymbol{x}\sim\mathcal N(\boldsymbol{\mu},\boldsymbol{\Sigma}),\]
则均值向量和协方差矩阵分别是
\[\boldsymbol{\mu}=\mathbb E[\boldsymbol{x}],\qquad
\boldsymbol{\Sigma}
=\mathbb E\!\left[(\boldsymbol{x}-\boldsymbol{\mu})
(\boldsymbol{x}-\boldsymbol{\mu})^\mathsf T\right].\]
要注意:\(\mathbb E[\boldsymbol{x}\boldsymbol{x}^\mathsf T]-\boldsymbol{\mu}\boldsymbol{\mu}^\mathsf T\) 是协方差矩阵,不是均值。
\(\boldsymbol{\Sigma}\) 具有以下性质:
\(\boldsymbol{\Sigma}\) 是对称半正定矩阵。
对任意向量 \(\boldsymbol{a}\),\(\boldsymbol{a}^\mathsf T\boldsymbol{\Sigma}\boldsymbol{a}\ge 0\)。
若 \(\boldsymbol{y}=\boldsymbol{A}\boldsymbol{x}+\boldsymbol{b}\),则
\[\mathbb E[\boldsymbol{y}]=\boldsymbol{A}\boldsymbol{\mu}+\boldsymbol{b},
\qquad
\operatorname{Cov}(\boldsymbol{y})
=\boldsymbol{A}\boldsymbol{\Sigma}\boldsymbol{A}^\mathsf T.\]
对联合高斯变量,协方差为零还会推出相互独立;对一般分布,“不相关”并不一定意味着“独立”。
联合概率密度 当 \(\boldsymbol{\Sigma}\) 正定时,\(d\) 维高斯分布的概率密度是
\[p(\boldsymbol{x})=
\frac{1}{(2\pi)^{d/2}|\boldsymbol{\Sigma}|^{1/2}}
\exp\left[-\frac12
(\boldsymbol{x}-\boldsymbol{\mu})^\mathsf T
\boldsymbol{\Sigma}^{-1}
(\boldsymbol{x}-\boldsymbol{\mu})\right].\]
指数中的二次型是马氏距离的平方。与一维中的“离均值多少个标准差”类似,它同时考虑了不同方向的尺度和变量之间的相关性。
图 1:协方差矩阵的特征向量决定椭圆方向,特征值决定各主轴方向上的尺度。
边缘分布与条件分布 将一个联合高斯向量分块:
\[\begin{bmatrix}\boldsymbol{x}_1\\\boldsymbol{x}_2\end{bmatrix}
\sim\mathcal N\!\left(
\begin{bmatrix}\boldsymbol{\mu}_1\\\boldsymbol{\mu}_2\end{bmatrix},
\begin{bmatrix}
\boldsymbol{\Sigma}_{11}&\boldsymbol{\Sigma}_{12}\\
\boldsymbol{\Sigma}_{21}&\boldsymbol{\Sigma}_{22}
\end{bmatrix}
\right).\]
边缘分布可以直接读出:
\[\boldsymbol{x}_1\sim\mathcal N(\boldsymbol{\mu}_1,\boldsymbol{\Sigma}_{11}),
\qquad
\boldsymbol{x}_2\sim\mathcal N(\boldsymbol{\mu}_2,\boldsymbol{\Sigma}_{22}).\]
已知 \(\boldsymbol{x}_2\)后,\(\boldsymbol{x}_1\) 的条件分布仍是高斯分布:
\[\boldsymbol{x}_1\mid\boldsymbol{x}_2
\sim\mathcal N(\boldsymbol{\mu}_{1\mid2},\boldsymbol{\Sigma}_{1\mid2}),\]
\[\boldsymbol{\mu}_{1\mid2}
=\boldsymbol{\mu}_1
+\boldsymbol{\Sigma}_{12}\boldsymbol{\Sigma}_{22}^{-1}
(\boldsymbol{x}_2-\boldsymbol{\mu}_2),\]
\[\boldsymbol{\Sigma}_{1\mid2}
=\boldsymbol{\Sigma}_{11}
-\boldsymbol{\Sigma}_{12}\boldsymbol{\Sigma}_{22}^{-1}
\boldsymbol{\Sigma}_{21}.\]
这组条件分布公式就是高斯过程回归的数学核心:把“已知训练点”和“未知测试点”组成一个大的联合高斯分布,再对训练点做条件化。
高斯过程 定义 若随机函数 \(f(x)\) 在任意有限输入集 \(X=\{x_1,\ldots,x_n\}\) 上的函数值
\[\boldsymbol{f}=
\bigl(f(x_1),\ldots,f(x_n)\bigr)^\mathsf T\]
都服从多元高斯分布,则称 \(f\) 服从高斯过程:
\[f(x)\sim\mathcal{GP}\bigl(m(x),k(x,x')\bigr).\]
其中
\[m(x)=\mathbb E[f(x)]\]
是均值函数,而
\[k(x,x')=
\mathbb E\!\left[(f(x)-m(x))(f(x')-m(x'))\right]\]
是协方差函数,也称核函数 。对给定的有限输入集,有
\[p(\boldsymbol{f}\mid X)
=\mathcal N(\boldsymbol{f}\mid\boldsymbol{m},\boldsymbol{K}),\]
其中 \(m_i=m(x_i)\),\(K_{ij}=k(x_i,x_j)\)。
可以把高斯过程理解为函数上的概率分布 。在观测数据之前,它给出函数先验;观测数据之后,不符合数据的函数概率降低,留下的函数形成后验分布。
核函数决定“函数像什么” 核函数衡量 \(f(x)\) 与 \(f(x')\) 的共变程度。为了构成合法的协方差矩阵,对任意有限输入集,核矩阵 \(\boldsymbol K\) 都必须是半正定的。
常用核函数包括:
常数核 \(k(x,x')=c\):所有位置具有相同相关性。线性核 \(k(x,x')=\sigma_b^2+\sigma_v^2xx'\):表达线性趋势。RBF 核(平方指数核) :
\[k(x,x')=\sigma_f^2
\exp\left[-\frac{(x-x')^2}{2\ell^2}\right].\]
其中 \(\sigma_f^2\) 控制函数的纵向幅度,长度尺度 \(\ell\) 控制函数变化速度:\(\ell\) 越大,函数越平滑。
Matérn 核 :允许比 RBF 核更粗糙、可微性更低的函数。周期核 :用于季节性或周期信号。
核还可以相加或相乘。例如“长期趋势 + 周期波动”可以由线性核和周期核相加表示。
图 2:两组函数都来自零均值高斯过程,但不同的长度尺度表达了不同的平滑性先验。
用 Cholesky 分解生成函数样本 在有限输入点 \(X\) 上,高斯过程采样就是多元高斯采样。先计算核矩阵
\[\boldsymbol K_{ij}=k(x_i,x_j),\]
再做 Cholesky 分解
\[\boldsymbol K+\varepsilon\boldsymbol I
=\boldsymbol L\boldsymbol L^\mathsf T.\]
对 \(\boldsymbol z\sim\mathcal N(\boldsymbol 0,\boldsymbol I)\),令
\[\boldsymbol f=\boldsymbol m+\boldsymbol L\boldsymbol z,\]
则 \(\boldsymbol f\sim\mathcal N(\boldsymbol m,\boldsymbol K)\)。其中很小的 \(\varepsilon\)(jitter)用于改善数值稳定性。
1 2 3 4 5 6 7 8 9 10 11 import numpy as npdef rbf_kernel (x1, x2, length_scale=1.0 , variance=1.0 ): distance2 = (x1[:, None ] - x2[None , :]) ** 2 return variance * np.exp(-0.5 * distance2 / length_scale**2 ) rng = np.random.default_rng(42 ) x = np.linspace(-3 , 3 , 200 ) K = rbf_kernel(x, x, length_scale=0.8 ) L = np.linalg.cholesky(K + 1e-8 * np.eye(len (x))) f = L @ rng.standard_normal(len (x))
高斯过程回归 观测模型 设真实的潜在函数为 \(f\),观测值含有独立高斯噪声:
\[y_i=f(x_i)+\epsilon_i,
\qquad
\epsilon_i\sim\mathcal N(0,\sigma_n^2).\]
记训练输入为 \(X\),训练输出为 \(\boldsymbol y\),测试输入为 \(X_*\)。定义
\[\boldsymbol K_y=K(X,X)+\sigma_n^2\boldsymbol I,\]
\[\boldsymbol K_*=K(X,X_*),
\qquad
\boldsymbol K_{**}=K(X_*,X_*).\]
为了突出核心公式,下面取零均值先验。训练观测与测试点处的潜函数值联合服从
\[\begin{bmatrix}
\boldsymbol y\\
\boldsymbol f_*
\end{bmatrix}
\sim\mathcal N\!\left(
\boldsymbol 0,
\begin{bmatrix}
\boldsymbol K_y & \boldsymbol K_*\\
\boldsymbol K_*^\mathsf T & \boldsymbol K_{**}
\end{bmatrix}
\right).\]
直接使用多元高斯的条件分布公式,得到后验预测分布
\[\boldsymbol f_*\mid X,\boldsymbol y,X_*
\sim\mathcal N(\bar{\boldsymbol f}_*,\operatorname{Cov}(\boldsymbol f_*)),\]
其均值为
\[\bar{\boldsymbol f}_*
=\boldsymbol K_*^\mathsf T\boldsymbol K_y^{-1}\boldsymbol y,\]
协方差为
\[\operatorname{Cov}(\boldsymbol f_*)
=\boldsymbol K_{**}
-\boldsymbol K_*^\mathsf T\boldsymbol K_y^{-1}\boldsymbol K_*.\]
这两个式子包含了高斯过程回归的主要直觉:
训练点通过核函数将信息传递给附近测试点。
测试点越远离已知数据,后验方差通常越大。
在数据密集的区域,不确定性会收缩。
若预测的是未来的含噪观测 \(\boldsymbol y_*\),还需要在后验协方差上加 \(\sigma_n^2\boldsymbol I\)。
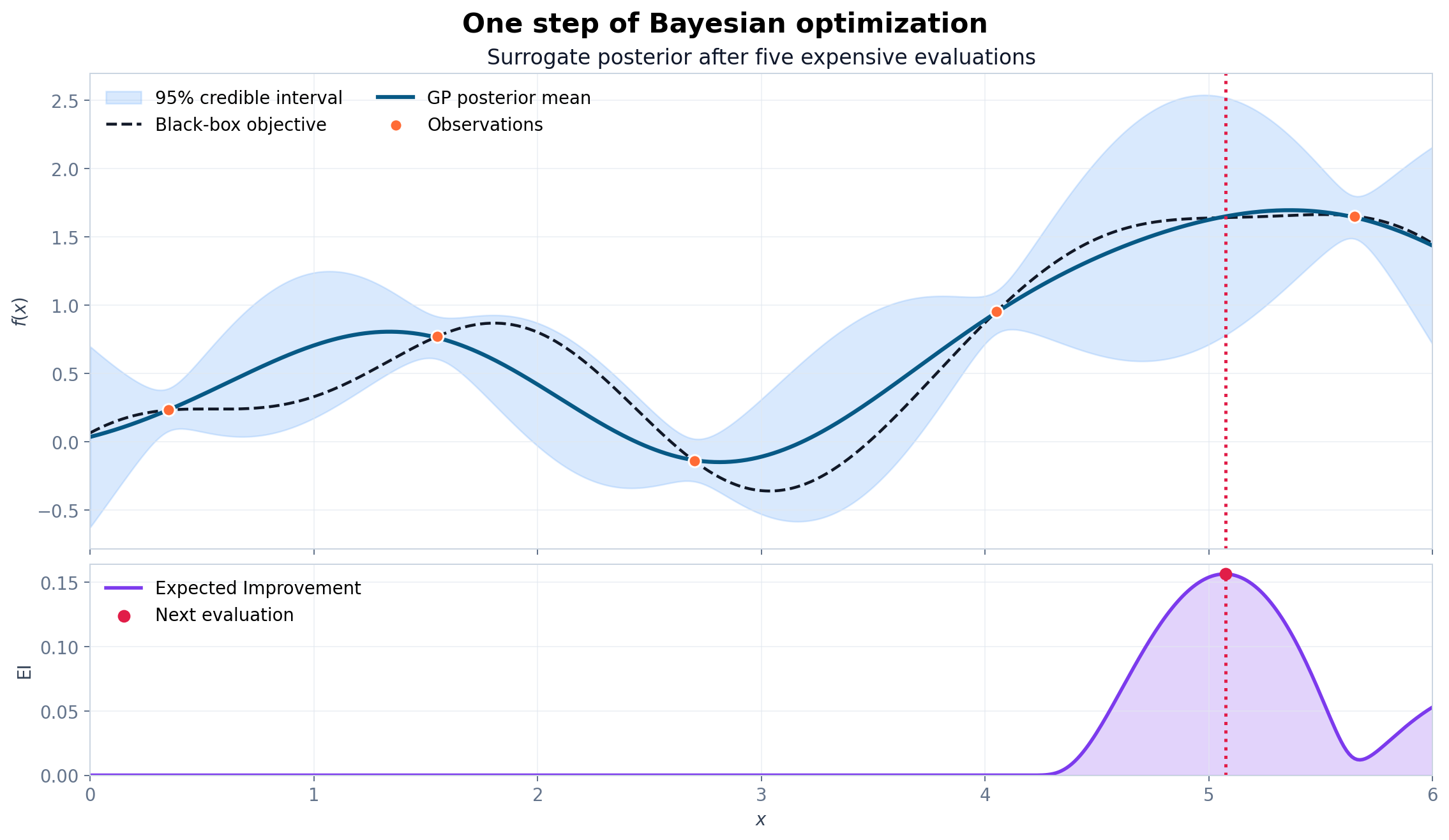
图 3:黑点是观测数据,蓝线是后验均值,浅蓝区域是约 95% 可信区间,细线是从后验中抽取的函数。
稳定的 Cholesky 计算 实际编程时不应显式计算 \(\boldsymbol K_y^{-1}\)。更稳定的做法是
\[\boldsymbol L=\operatorname{chol}(\boldsymbol K_y),\]
然后通过两次三角方程求解
\[\boldsymbol\alpha
=\boldsymbol L^{-\mathsf T}\boldsymbol L^{-1}\boldsymbol y.\]
于是
\[\bar{\boldsymbol f}_*=\boldsymbol K_*^\mathsf T\boldsymbol\alpha.\]
再令 \(\boldsymbol V=\boldsymbol L^{-1}\boldsymbol K_*\),则
\[\operatorname{Cov}(\boldsymbol f_*)
=\boldsymbol K_{**}-\boldsymbol V^\mathsf T\boldsymbol V.\]
这样避免了显式求逆,通常更快、误差也更小。标准高斯过程回归的训练主要需要对 \(n\times n\) 核矩阵做分解,时间复杂度约为 \(\mathcal O(n^3)\),存储复杂度约为 \(\mathcal O(n^2)\)。
如何选择核参数 长度尺度 \(\ell\)、信号方差 \(\sigma_f^2\) 和噪声方差 \(\sigma_n^2\) 等超参数,通常可以通过最大化对数边缘似然学习:
\[\log p(\boldsymbol y\mid X)
=-\frac12\boldsymbol y^\mathsf T\boldsymbol K_y^{-1}\boldsymbol y
-\frac12\log|\boldsymbol K_y|
-\frac n2\log(2\pi).\]
这三项可以分别理解为:
数据拟合项 :模型要能解释观测值。复杂度惩罚 :过于灵活的模型会付出代价。归一化常数 。
因此,边缘似然自然地在数据拟合和模型复杂度之间做权衡。
从直觉上再理解一次 高斯过程回归可以被概括为下面四步:
用均值函数和核函数表达对未知函数的先验假设。
把训练点和测试点放入同一个联合高斯分布。
以已观测的 \(\boldsymbol y\) 为条件,得到测试点上的后验分布。
用后验均值做点预测,用后验方差表达不确定性。
它是“非参数模型”,并不是说没有参数,而是说模型复杂度会随数据增长,我们没有预先把未知函数限定在某个固定维数的参数形式中。
小结 高斯过程的数学基础其实可以浓缩成一条主线:
多元高斯分布可以稳定地做边缘化和条件化;核函数将这种有限维的高斯结构扩展到函数空间;观测数据后,再用条件高斯公式从先验得到后验。
理解了多元高斯的几何意义、条件分布和核矩阵,高斯过程的公式就不再是凭空出现的。
参考资料
《Python 贝叶斯分析》附录 C:高斯过程 多元高斯分布完全解析 Jie Wang, An Intuitive Tutorial to Gaussian Process Regression Carl E. Rasmussen and Christopher K. I. Williams, Gaussian Processes for Machine Learning